
안녕하세요 오늘은 일반기업 뿐만 아니라 공공기간에서 가산점을 주는 곳이 늘어나는 빅데이터 분석기사 시험 후기를 작성하려고 합니다.
우선 후기를 작성하기 위해서는 합격 인증을 해야 하니 점수표를 올리도록 하겠습니다.
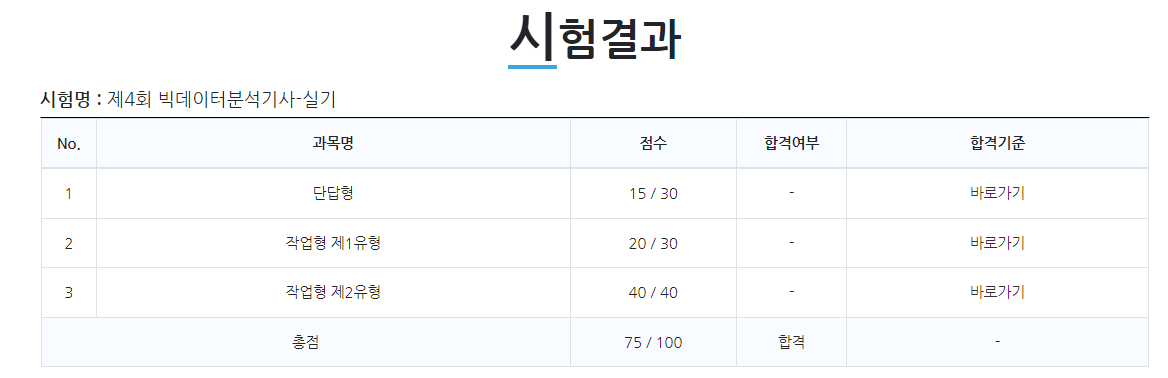
저는 총 75점이라는 점수로 합격하였습니다.
처음에 해야 할 일은 각 과목마다 목표점수가 중요합니다.
1. 단답형
1문제 당 3점이고 총 10문제 입니다. 무조건 여기서는 4개 이상은 맞아야 합니다.
4개를 맞던 6개를 맞던 똑같다고 할 수 있습니다. 왜냐면 시험당락을 결정하는 단위가 10점 단위라서 12점과 18점은 동일하게 10점 이상 점수이기 때문입니다.
따라서 4문제를 맞으면 다른 과목에서 50점 이상을 목표로 해야하며 7문제 이상을 맞춘경우 다른과목에서 40점 이상만 맞으면 되기 때문에 훨씬 합격 확률은 올라갑니다.
물론 필기를 보았다면 쉽겠지만, 필기를 벼락치기 한다면 이또한 쉽지 않은 과정입니다.
거의 합격자의 많은 수가 4개 이상을 목표로 준비합니다.
2. 작업형 제 1유형
Pandas의 DataFrame을 다루는 문제라고 해도 과언이 아닙니다.
이말은 Pandas의 DataFrame만 다루면 최소한 2문제 이상은 맞춘다고 할 수 있습니다. 추가로 Numpy를 할 수 있다면 좀 더 수월하게 문제를 접근 할 수 있지만, 시간이 없다면 무조건 df만 다루시길 바랍니다.
작업형 제 1유형은 어떻게 준비해야 하며, 문제는 어떤 식인지 궁금하다면 우선 빅데이터 분석기사 응시환경을 체험해보시길 부탁드립니다. 바로 구름이라는 IDE에서 시험을 보는데 아래 경로에 들어가보면 됩니다.
https://dataq.goorm.io/exam/116674/%EC%B2%B4%ED%97%98%ED%95%98%EA%B8%B0/quiz/2
구름EDU - 모두를 위한 맞춤형 IT교육
구름EDU는 모두를 위한 맞춤형 IT교육 플랫폼입니다. 개인/학교/기업 및 기관 별 최적화된 IT교육 솔루션을 경험해보세요. 기초부터 실무 프로그래밍 교육, 전국 초중고/대학교 온라인 강의, 기업/
edu.goorm.io
위에 들어가보면 아래와 같이 실제 시험과 동일한 환경에서 문제를 풀어볼 수 있습니다.
아래 문제를 보고 어렵다고 느낀다면, 아래와 같은 수식은 기본적으로 공부하시기 바랍니다.
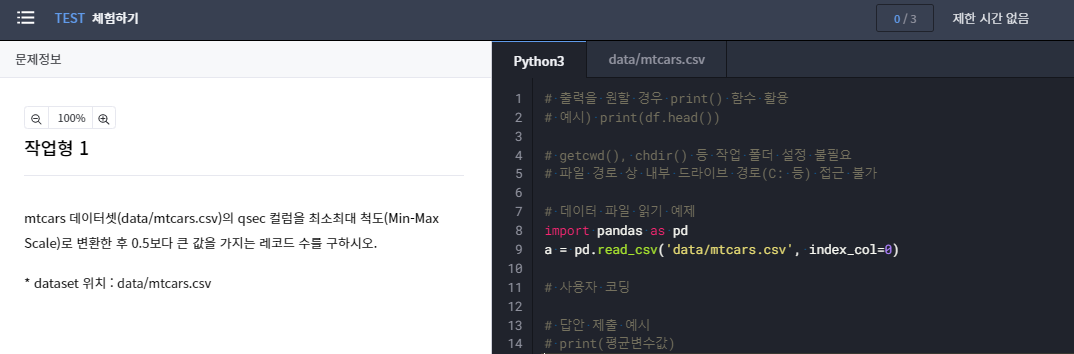
가장 많이 사용하는 함수는 인덱스를 접근하는 df.loc / df.iloc 입니다.
그리고 df 변환시 대괄호 2개 [[]] / 대괄호 1개 [] 이 차이는 큽니다. [[]] 두개의 경우 결과도 dataframe이지만 []의 경우는 series라는 자료형으로 출력되므로, 알고 있던 dataframe의 함수들이 사용될 수 없기 때문입니다.
이럴경우 해결 방법은 pd.DataFrame('Series 변수입력')으로 시리즈를 dataframe으로 변경 가능합니다만, 이것 또한 시간낭비 이므로 보통 대괄호 2개를 많이 사용합니다.
DataFrame 함수 중 중요한 건 아래와 같습니다.
- replace 함수 사용 예시 : df['industry).replace()
- columns 이름변경 하기 예시 : df.columns = ['A', 'B', 'C'..]
- 컬럼값들의 갯수 확인 : df['컬럼'].value_counts()
- DataFrame 합치기 : df.concat([df1, df2, df3..], axis=1)
- 저장하기 : DataFrame.to_csv('파일이름.csv', encoding='실제 시험에는 encoding은 입력안해도 된다.')
- Boxplot 그리기 : df.boxplot(column='컬럼명')
- 컬럼값들의 오름차순, 내림 차순 정리 : df['컬럼'].sort_values(asceding=False(내림차순), True(오름차순))
DataFrame 중 통계관련 함수입니다.(여기서 가장 많이 쓰이는 건, 요약과 사분위수, 분산, 표준편차 정도입니다.)
- 요약 : df.describe( )
- 왜도 : df.scew( )
- 첨도 : df.qurtosis( )
- 표준편차 : df.std( )
- 분산 : df.var( )
- 사분위수 : df.quantile( 0.25 0.5 0.75)
- 상관관계 df.corr( )
- 공분산 : df.cov( )
위에 함수들만 자유롭게 구사한다면 최소한 작업형 1에서 2문제 이상은 맞을 수 있습니다.
저또한 위에 함수들은 자유롭게 구사하기 위해 아래 케글에서 여러문제들을 풀어보았습니다.
하지만 결국 가장 중요한건 10개 정도 문제를 끊임없이 지속적으로 풀어서 자동암기하는 것입니다.
왜냐면 시험장에 가서 직접 암기하여 코드를 작성해야 하기 때문입니다.
더 다양한 데이터 관련 문제는 아래 캐글을 활용하세요
https://www.kaggle.com/datasets/agileteam/bigdatacertificationkr
Big Data Certification KR
빅데이터 분석기사 실기 (Python, R tutorial code)
www.kaggle.com
작업형 2에 대해서는 다음 글에서 다루도록 하겠습니다.
이글에서 저의 4회시험 준비 후기의 핵심은..
중요한 건 끊임없이 반복하는 것 같습니다.
저의 경우는 실기는 2주 정도 약 하루에 2~3시간 준비하였습니다.
처음 일주일은 작업형 1에 대해서 2,3회 기출문제를 6개를 거의 외우다 시피 타이핑을 했습니다.
그리고 캐글에서 랜덤하게 문제를 접하였을 때 60~70% 정도 바로 해결 할 수 있다면 작업형 1은 그만 하셔도 됩니다.
그리고 4회 시험의 경우도 기존 2,3회와 동일한 난이도 수준으로 작업형 1은 출시되었습니다.
하지만 정보처리기사 처럼 어느순간 갑자기 어려워지는 순간이 올 것이므로 빠르게 획득하는 것이 중요합니다.
'딥러닝,패턴인식,빅데이터' 카테고리의 다른 글
| 빅데이터분석기사 체험하기 정답 (0) | 2022.08.03 |
|---|---|
| 빅데이터 분석기사 3회 기출문제 풀이(2) (0) | 2022.08.03 |
| 빅데이터 분석기사 3회 기출문제 풀이(1) (0) | 2022.08.03 |


