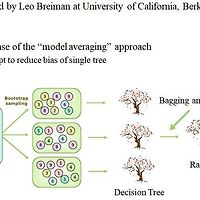
2018/02/24 - [딥러닝,패턴인식/패턴인식] - 의사결정트리 / 랜덤 포레스트 / 부스팅 / 배깅 (Decision Tree / Forest) part.1
2018/02/25 - [딥러닝,패턴인식/패턴인식] - 의사결정트리 / 랜덤 포레스트 / 부스팅 / 배깅 (Decision Tree / Forest) part.2
2018/02/25 - [딥러닝,패턴인식/패턴인식] - 의사결정트리 / 랜덤 포레스트 / 부스팅 / 배깅 (Decision Tree / Forest) part.3
오늘은 유전 알고리즘(Genetic Algorithm)에 대해서 정리해볼려고 한다.
여기서는 2진수로 접근하는 것이 아닌 10진수의 실제 정답을 찾는 방법으로 접근을 할 것이다.
유전알고리즘의 기본적인 시퀀스는 아래와 같다. 임이의 데이터셋이 있다고 치면 그 값들 중 몇몇개를 선택하고 교차도 하고 변이를 하면서 새로운 데이터셋이 형성이 되고 그 값은 에러가 적은 값 부근에서 많은 데이터 셋들이 만들어진다고 생각하면 된다.
데이터셋이라고 하니 이해가 안될 수 있을텐데 단순하게 선형회귀(Linear Regression)를 진행한다고 할때 여러개의 기울기와 바이어스를 갖는 값들이 만들어 지는데 각각의 조합이 여기서 말하는 Popultion이라고 생각하면 된다(위에서 말한 데이터셋/에러를 최소화 하는 정답). 물론 2진수로 설명을 많이 하지만 10진수로 바로 적용해서 문제를 풀린다.
(gradient, bias) ▶ (1, 2) / (2, 4) / (2, 5).....등등등등 수많은 조합이 생성된다.
우리는 그중에 각각 포인트들을 가장 잘 표현해내는 기울기와 바이어스를 찾으면 되는 것이고 여기서 fitness value 값은 선형회귀된 그래프와 각각의 샘플의 차이, 즉 오차라고 말할 수 있을 것이다.

당연히 에러가 작은(정답과 가까운 혹은 fitness value가 높은 값을 값일 수록 그 주변에 데이터를 이용해서 에러를 보는 것이 맞을 것이다. 따라서 fitness value가 높은 값 주변으로 많은 데이터를 샘플링하는 방법이 롤렛휠선택(Roulette wheel selection) 방법이다. 롤렛을 돌리는데 모양을 에러를 작게 만드는 population이 더 많이 나오도록 설정을 해놓은 방법이다. 아래 Universal sampling은 균등한 확률로 poplution을 뽑는 방법이다. 당연히 Roulette wheel selection 방법이 빠르게 찾겠지만 더 많은 영역을 sweep하는 것은(local minimum에 빠지는 것을 방지) Universal sampling 방법일 것이다.

위에 설명대로 Population 중에서 fitness value가 높은 몇몇 조합을 선정을 하고 난 이후에는 교차(Crossover)와 변이(Mutation)를 이용하여 정답과 비슷한 영역 부근에서 다른 정답의 조합을 만들어 보는 것이다. 만약에 기울기와 바이어스 조합이 (1,5) 였을때 가장 fitness가 좋았다고 하면 그 조합이 여러번 선정됬을 것이고 다른 조합과 교차, 변이를 통해서 (1.1 , 5.1) (0.95 , 5.3), (0.9, 4.9)..등과 같은 주변의 값이 생겨나고 이것들이 다시 fitness value 계산을 통해서 에러가 최소화 되는 값들로 선정이 되는 방법이다. 아래는 교차의 여러방법을 설명한다. 크게 Discrete crossover와 Line Crossover 마지막으로 Intermediate crossover가 있으며 그림과 예시를 통해서 쉽게 이해할 수 있을 것이다.

Discrete crossover 방법은 sample이라는 지표를 이용하여 각각의 Population에서 교차를 직접 시키는 방법이다. 즉 이전 세대(부모세대,parents)의 population이 (1,4) (3,5)라고 한다면 새롭게 만들어지는 조합은 (1,5) (3,4)가 되는 것이다.
Line crossover는 Alpha값을 이용하여 이전세대 값에 곱해줌으로써 새로운 조합의 population이 만들어지는 것이다.
마지막으로 Intermediate는 아래와 같은 방법을 통해서 좀 더 다양한 조합으로 다음세대 population(자손세대,offspring)이 생성된다.

변이(mutation)는 갑자기 특별한 값을 적용시켜봄으로써 혹시 정답과 다른 영역에서 정답을 찾고 있다면 (local minimum) 거기서 빠져나오도록 도와준다. 즉 global minimum을 찾게끔 도와준다라고 생각하면 된다. 물론 mutation이 발생되는 규칙은 많이 존재하고 사용자가 직접 만들수도 있다.
왼쪽 아래 그림과 같이 빨간색 원이 변이를 통해서 주변의 다른 영역으로 population이 형성되는 것을 확인 할 수 있다.
즉 (3, 4)인 값이 바이어스는 고정되고 기울기만 변경되는 값인 (5, 4) (1, 4)와 같은 값으로 변화가 되는 것이다.

또한 삽입을 통해서 새로운 자손이 만들어지기도 한다. 이러한 삽입방법도 local minimum에서 빠져나올 수 있도록 하는 방법중에 하나이다. 물론 교차, 변이, 삽입등을 다양하게 사용할 수 있지만 그렇게 되면 iteration 수가 늘어나게 될 수 있으므로 잘 고려해야 할 것이다. 모든 패턴문제가 직면하는 문제이지만 정확도를 올릴지, 속도를 빠르게 할지는 프로젝트마다 알아서 잘 설정해야 하는 중요한 문제이다.

이 위에 글을 읽고 이해를 했다면 아래 그림을 보고 아~라는 감탄사가 나올것이다. 느낌이 오겠지만 현재까지의 지식으로는 유전알고리즘은 약간은 랜덤으로 정답을 찾는 방법이라고 느낌이 생길 수 있지만 iteration이 진행될 수록 정답의 주변에서 offspring population이 생성되는 것을 확인 할 수 있을 것이다. 랜덤요소가 들어가 있어서 정답을 찾는데 시간은 오래걸린다는 단점이 있다. 하지만 요즘에는 그것들을 해결할 수 있는 adaptive한 유전 알고리즘들이 많으니 찾아보길 바란다.
아래 그림이 유전알고리즘을 설명하는 전부이다. 부디 이 글이 유전알고르즘 기본을 이해하는데 도움이 되었으면 한다. 틀린점이나 궁금한 점은 댓글을 달아주세요

'소프트웨어 > 패턴인식' 카테고리의 다른 글
| 의사결정트리 / 랜덤 포레스트 / 부스팅 / 배깅 (Decision Tree / Forest) part.3 (7) | 2018.02.25 |
|---|---|
| 의사결정트리 / 랜덤 포레스트 / 부스팅 / 배깅 (Decision Tree / Forest) part.2 (0) | 2018.02.25 |
| 의사결정트리 / 랜덤 포레스트 / 부스팅 / 배깅 (Decision Tree / Forest) part.1 (0) | 2018.02.24 |